Netflix Recommender System
This a personal project in which I create a recommender to recommend netflix tv shows and movies to watch based on the similarity to the movies and tv shows I selected.

Unfortunately, the world in currently in the midst of a global pandemic and here in the UK we are currently in a lockdown where we have to stay indoor and avoid going outside unless necessary. During this time, I decided to make a positive out of a negative and I have furthered my skills, but I have also relaxed a bit. One way I have done so is by watching tv shows and movies. But personally, I find it hard to find and start new tv shows and movies because there is so much to watch and I don’t want to spend all day searching for a new series or movie. So, with that in mind I decided to make the process easier with a recommender system.
What is a recommender system?
Recommender system are software tools and techniques that provide recommendations or suggestion for items that they thinking the user will want or be useful to them \([1]\). There are various examples of recommender systems that are used in the real world e.g. Amazon, YouTube, Spotify. Recommender system mainly use two approaches: Collaborative and content-based filtering. Collaborative based filtering uses a database about user preferences to predict additional topics or products a new user might like based on user with similar preferences to them \([2]\). Content based filtering looks at the content of the item and recommend items which have similar contents. I decided to go with content based over collaborative because the collaborative filtering assumes that the user interests in the item they would be recommended wont change or vary. Which is unlikely as people grow and sometime have different interests. Whereas the content of the item won’t change over the time in my case with tv shows and movies. With the background we can begin the building of the recommender.
Tools and environments
- Python 2.7
- Jupyter Notebook
- Pandas
- NLTK
- Scikit-learn
Dataset
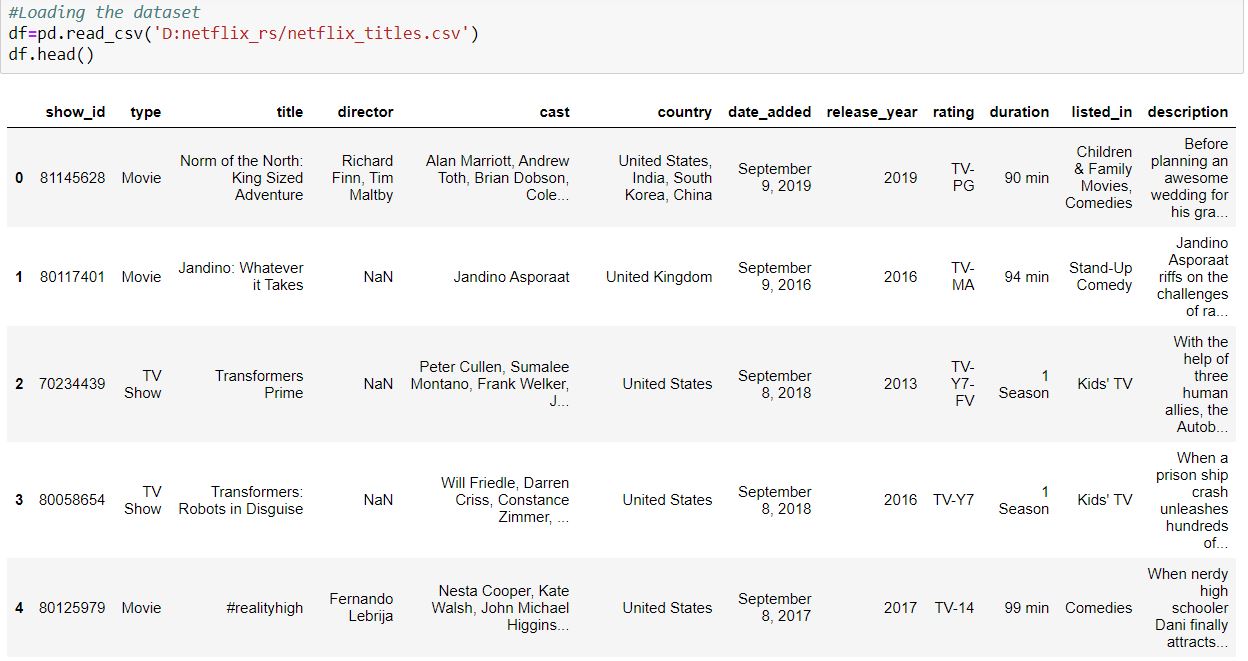
Dataset retrieved from Kaggle is here which contains information about tv show and movie from Netflix such as director, cast and description of the plot.
Exploratory Data analysis (EDA)
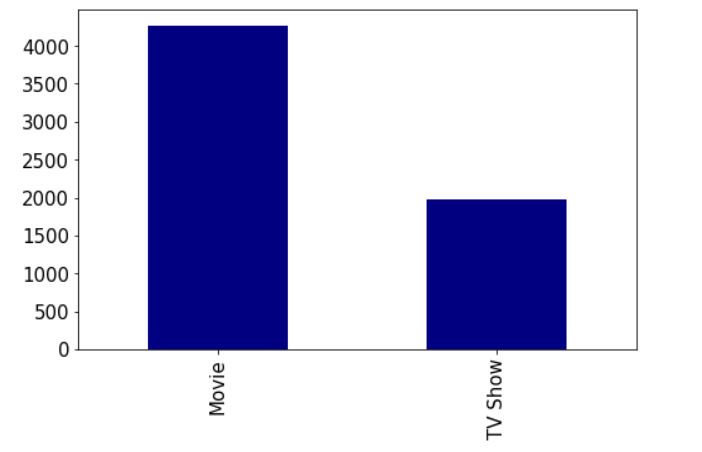
Performed some EDA on the data. Found that there were a lot more movies than tv shows which makes sense given their history and origins.
Preprocessing
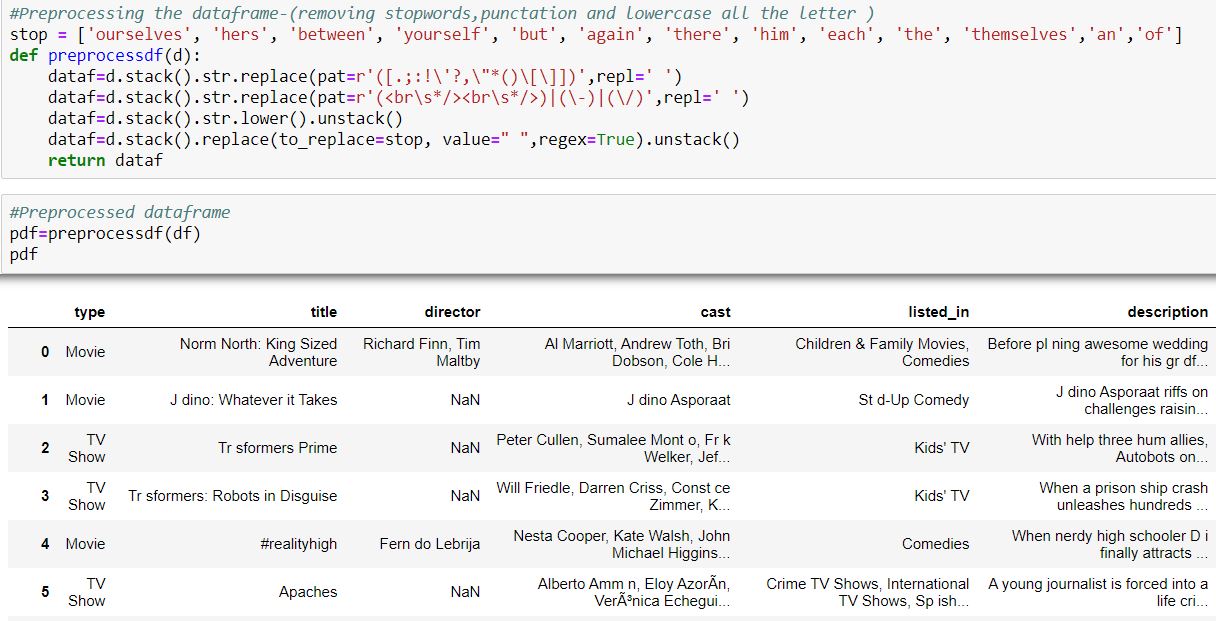
Pre-processing of the data include various techniques such as:
- Punctation removal
- Stop word removal
- Making all the words lowercase
Raking
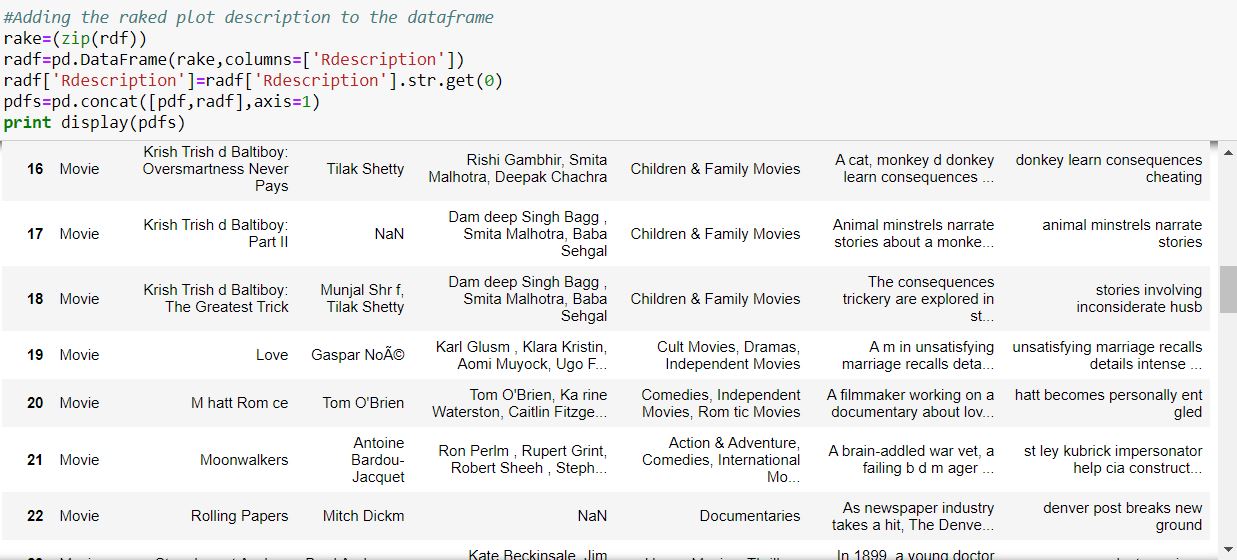
Using the rake function from NLTK to extract key phrases from the plot description.
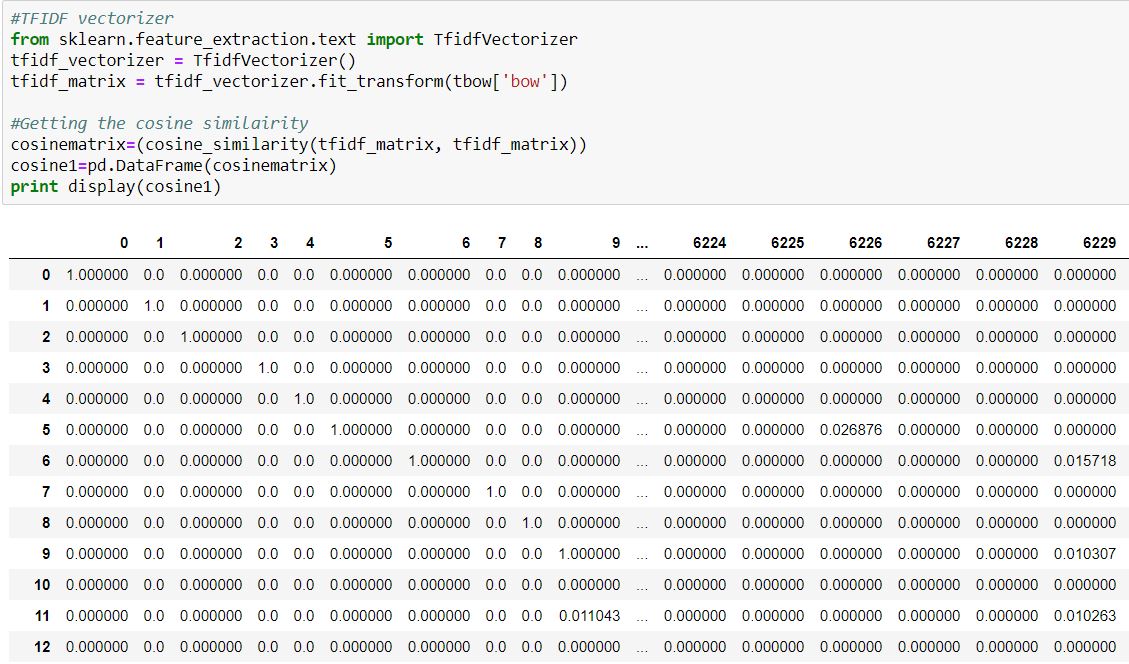
Term frequency–inverse document frequency (tf–idf) and cosine similarity
tf–idf is a statistic that reflect how important the word is to the document \([3]\). The cosine similarity looked at how similar two words are and is one of the most common methods when looking at text data.
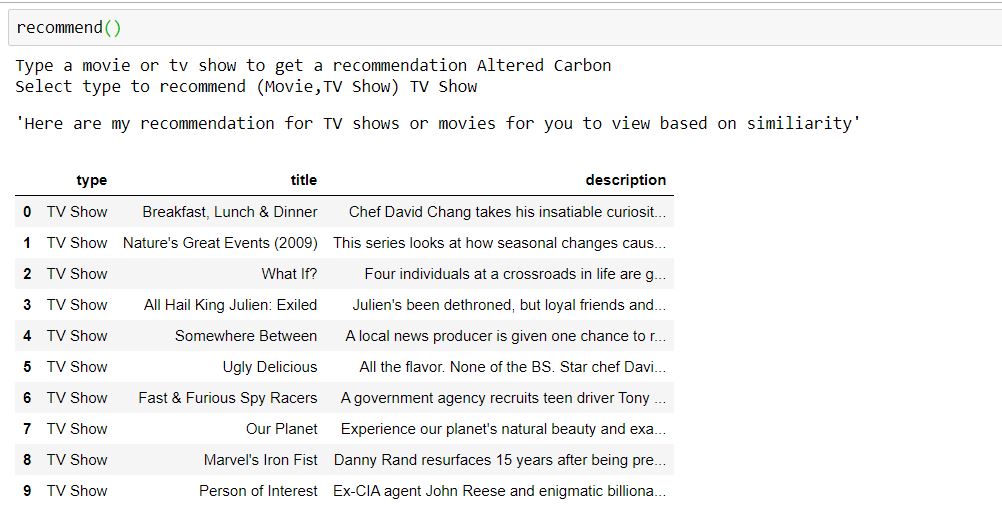
Recommender
Here are some of the recommendation made using some shows and movies that I have watched or am currently watching. As you can see there are recommendations are pretty similar in content but there are some unusual recommendations. But I have viewed some of the recommendations and am pleased to say that I was able to pick up some new shows and movies that I wouldn’t have otherwise found. So, the recommender can recommend tv shows and movies, but it is a bit of hit and miss with some recommendations it may be due to certain factors e.g. not too many similar shows/movie in the dataset or having similarities in unimportant features e.g same director but different genre and plot.so I would have to make more additions to get recommended more tv shows and movies that I might enjoy. But it is useful and can be applied other industries to make recommendation appropriate to that industry.



Possible improvements or additions
- Addition of more filtering options e.g. filter by country, duration of show/movie
- Increase the dataset by including other streaming service (Hulu, apple, Disney) data
- Calculating and displaying the probability that the user will like the recommended tv shows and movies.
References
[1] Ricci, F., Rokach, L. and Shapira, B., 2010. Introduction To Recommender Systems Handbook. [online] Springer Link. Available at: https://link.springer.com/chapter/10.1007/978-0-387-85820-3_1 [Accessed 2020].
[2] Breese, J., Heckerman, D. and Kadie, C., 1998. Empirical Analysis Of Predictive Algorithms For Collaborative Filtering | Proceedings Of The Fourteenth Conference On Uncertainty In Artificial Intelligence. [online] Dl.acm.org. Available at: https://dl.acm.org/doi/10.5555/2074094.2074100 [Accessed 1 May 2020].
[3] Leskovec, J., Rajaraman, A., Labs, M. and Ullman, J.D. (2016). Mining of Massive Datasets. [online] Available at: http://infolab.stanford.edu/~ullman/mmds/book.pdf [Accessed 9 Jul. 2019].